5/20/2026 at 2:11:57 AM
For those who would like to know the total and active parameter count of this model: even though Google doesn't disclose the model technicals, we can infer them within relatively tight margins based on what we do know.We know they serve the model on TPU 8i, which we have plenty of hard specs for (so we know the key constraints: total memory and bandwidth and compute flops). We can also set a ceiling on the compute complexity and memory demand of the model based on knowing they will be at least as efficient as what is disclosed in the Deepseek V4 Technical Report.
We can also assume that the model was explicitly built to run efficiently in a RadixAttention style batched serving scenario on a single TPU 8i (so no tensor parallelism, etc. to avoid unnecessary overheads... Google explicitly designed the 8th-generation inference architecture to eliminate the need for tensor sharding on mid-sized models).
We know Google intends to serve this model at a floor speed of around 280 tok/s too.
Putting all these pieces together, we can confidently say this model is ~250-300B total, and 10-16B active parameters. Likely mostly FP4 with FP8 where it matters most.
Visual:
┌────────────────────────────────────────────────────────┐
│ TPU 8i VRAM (288 GB) │
├───────────────────────────┬────────────────────────────┤
│ Static Model Weights │ Dynamic Allocations & │
│ (250B - 300B @ Mixed │ Compressed KV Caches │
│ FP4/FP8) │ (RadixAttention / SRAM) │
│ ~110 GB - 150 GB │ ~138 GB - 178 GB │
└───────────────────────────┴────────────────────────────┘
Edit: There's one factor I under-rated in my initial estimate... TurboQuant. This is a compute to KV memory use tradeoff. It's plausible with TurboQuant at a quality-neutral setting they've gotten the model up to 400B with similar economics. This is a variable effecting concurrency and the the way they decided total model size was likely based on what they see for the average user's average KV cache depth in real-world usage.
by easygenes
5/20/2026 at 3:24:52 AM
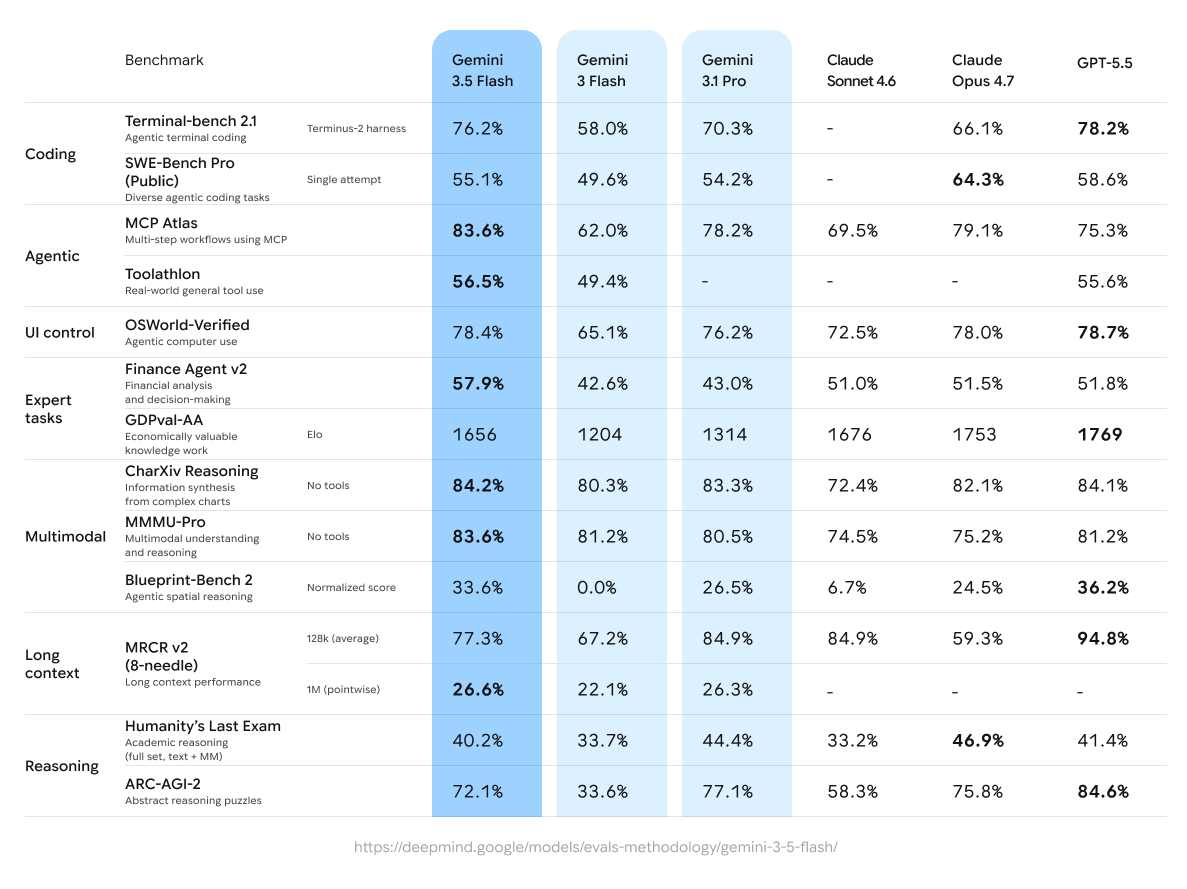
We've been really impressed with the performance of ~30B parameter class models and how close they are to the frontier from ~6-12 months ago, which begs the question, are the frontier labs really serving 10T parameter models? Seems unlikely.If these Gemini 3.5 numbers are accurate, then I'd wager GPT 5.5 and Opus 4.7 are a lot smaller than people have speculated, too. It's not that frontier labs can't create a 5T+ parameter model, but they don't have the data to optimize a model of that size.
Gemini 3.5 Flash is really smart in one-shot coding reasoning, btw. Near the frontier. But it doesn't do so well in long horizon agentic tasks with arbitrary tool availability. This is a common theme with Google models, and the opposite of what we see with Chinese models (start dumb, iterate consistently toward a smart solution).
Data at https://gertlabs.com/rankings
by gertlabs
5/20/2026 at 7:03:32 AM
Elon says Opus is 5T (and I would expect he'd know)> It's not that frontier labs can't create a 5T+ parameter model, but they don't have the data to optimize a model of that size.
The have plenty if data. They use very large amounts of verifiable synthetic data in (lots in coding and math) cover the gap.
Also the frontier labs are paying people to do tasks, tracking the trajectories and training on that. Most of the optimization is in RL based on these trajectories.
by nl
5/20/2026 at 12:16:41 PM
> Elon says Opus is 5T (and I would expect he'd know)Even if he knew, why would anyone expect Elon not to lie about anything?
> The have plenty if data.
I don't think data is the problem either, but compute is: if you want to train your 5T params model like modern small models are being trained (with a thousands time more training tokens than params), that's an enormous training run.
by stymaar
5/21/2026 at 3:08:06 AM
> if you want to train your 5T params model like modern small models are being trained (with a thousands time more training tokens than params), that's an enormous training run.Yes it is. Spending $100M on training runs is common, and $1B might be in scope for some of the large models.
Sonnet 3.5 cost "a few 10s of millions of dollars" back in 2024: https://simonwillison.net/2025/Jan/29/on-deepseek-and-export...
by nl
5/21/2026 at 12:02:24 AM
I mean in general I'm pretty doubtful about things he says, but in this he was comparing Grok and it sort of makes sense in the context: https://x.com/elonmusk/status/2042123561666855235by nl
5/21/2026 at 10:54:01 AM
In that context specifically, why would you trust him not to lie?He's using a massive number for Opus to make Grok look good “for its size”.
If he said something praising Anthropic and like “Grok is 7T, while Opus is better while being only 5T, we need to work harder” or something then maybe I could believe it. But here it's a context where he has all the incentives to inflate Opus' size to make himself look somehow “in the race” when he really isn't despite the money and compute advantage.
Given this tweet I wouldn't be surprises if Grok was actually 1T and Opus being in the same ballpark.
And I'm absolutely not buying current-days Sonnet being a 1T parameters model (that's an absolutely deranged take: that would make Anthropic already behind Chinese model makers, which I think isn't something anyone would put money on).
by stymaar
5/20/2026 at 7:33:16 AM
This is what we do at gertlabs.com - the foundation labs are actually starving for better data. Having quality data is not the same as having a lot of data. Human curated data / RLHF cannot scale to a 5T model and synthetic data pipelines are very much a work in progress in the industry.Some interesting notes:
- Training a small model with large model output resulted in LESS improvement than distilling a less smart model onto the same small architecture [0]. We are starting to hit intelligence density limits in small models (<30B models may be nearing saturation now)
- good RL environments incidentally also make for good benchmarking
by gertlabs
5/20/2026 at 10:49:23 AM
Wouldn’t it be good to start investigating into a micro model architecture? Like first model checks the context and routes to the Java optimized model, etc. would make it also simpler to load/unload models in memory.So extremely small models that are only good for a certain task like programming languages. A little bit of a model at the front that is extremely good in classification of tasks and than a more complex model that can bring each of these micro models back together
by merb
5/20/2026 at 11:07:51 AM
My guess is that we underestimate how much non-Java data and context in general is needed to create a good Java coding model. It could be true that a good Java model would be of 80-90% the size of a comparable overall coding model.Obviously, I have no idea but I guess it’s not as simple as “just train only on Java code and reduce size to 1/10th”.
by lukeundtrug
5/20/2026 at 11:01:06 AM
I think you're describing Mixture-of-Experts.by puilp0502
5/20/2026 at 12:09:54 PM
> they don't have the data to optimize a model of that size.So where does humanity cap out? The statement more or less implies that there's a ceiling of our ability to train models which might be below what LLMs are capable of (e.g. not AGI but how good coding agents they might ever become, for example).
by KronisLV
5/20/2026 at 7:37:12 AM
I’m not sure if synthetic data is enough.Xai paying cursor to train models with their data, tell us that having an agent tool like claude code is important for quality data acquisition. That’s why they recently shipped grok build
I think we will see insane SOTA models from xai in the next few months.
by maipen
5/20/2026 at 3:30:14 AM
We know from NVIDIA's public Vera Rubin inference engine marketing materials that the frontier lab models are ~1-2T total.Mythos is an exception that's larger.
by easygenes
5/20/2026 at 6:02:59 PM
Wouldn’t that be an exciting plot twist? That the release cadence of the big labs doesn’t actually reflect any meaningful improvements, or bigger models, but it’s a marketing ploy to start ratcheting up prices for good ARR numbers prior to the big IPO where the celebrity executives bail out of the stalling plane.by opsnooperfax
5/20/2026 at 6:22:58 AM
I agree with this sentiment but the reasoned anecdotes do not agree. I imagine the flagship models have modalities/usages that we hn-ers don't imagine easily.by beacon294
5/20/2026 at 9:01:08 AM
It was estimated that Mythos is 10T.And serving is not training. For distilling you need to train the big models to have something to be distilled.
by Glohrischi
5/20/2026 at 4:38:09 AM
I exclusively use gemini models and this has been my experience.I mitigate it by creating dense planning docs for everything and executing iteratively.
Lot's of time wasted on procedure unfortunately
by MisterPea
5/20/2026 at 10:07:50 AM
If two things hold up - 1) this is actually a 2-300B parameter model and 2) this is actually competitive with frontier OpenAI and Anthropic models (and not just benchmaxing), the implications are pretty big. It would mean you could run "frontier level" performance in one box at home.300B models at least fit in a single maxed out Mac Studio or a small stack of DGX Sparks or AMD Strix Halo boxes.
For comparison, DeepSeek V4 Flash is all the rage now for small efficient models. It's very good for its size but far from the performance of the latest GPT Pro and Opus models. The vanilla variant has 284B parameters. It fits on both 256GB and 512GB Mac Studios and hits about 20-30 tokens/second.
The implication of all this here is that you could have a (somewhat sluggish) Opus in a small box at home. At least once competing models and hardware to run them will be available (high end Mac Studios have been discontinued).
Something tells me that this means that Google's performance numbers here are inflated.
by DCKing
5/20/2026 at 2:30:17 PM
Opus is estimated to be around 4T parameters, and 5.5 around 9T. [1] And while 3.5 at least qualifies to be in the same neighborhood, which is stunning if these numbers are all true, it may be that closing that last ~10% difference needs 50x more parameters.by WarmWash
5/21/2026 at 12:19:26 AM
Their methods are only calibrated on open models (of course) and they admit very broad confidence bounds. You can also just see from comparing their estimates of the same models at different reasoning levels that there are major confounders to this. I would err on the absolute lowest side of their estimates for frontier models (e.g. 3T for GPT-5.5, 1.5-2T for Opus 4.5+).by easygenes
5/20/2026 at 12:03:14 PM
> the implications are pretty big. It would mean you could run "frontier level" performance in one box at home.That wouldn't surprise me at all actually, models like Qwen3.6-35B are comparable to frontier level models from a year ago and I wouldn't be surprised if we had self-hostable open weight models matching Opus 4.7 in a year. Assuming that Google has one year of advance against Chinese lab isn't far fetched given how much resources they have compared to their Chinese competitors.
by stymaar
5/20/2026 at 12:14:01 PM
I think there was a leap around Opus 4/4.1 that hasn't quite been equalled by self hostable models yet. Perhaps full Kimi K2.6 and Deepseek V4 Pro can achieve Opus 4.1 levels (it's hard to compare anyway, benchmarks are largely a game nowadays), but both of these are also north of 1000B parameters and therefore really impractical to run at home for the foreseeable future.It's not yet obvious to me that you can achieve the breakthrough performance of say Opus 4.1/4.5 in a number of parameters you can swing at home.
by DCKing
5/20/2026 at 1:39:36 PM
> It's not yet obvious to me that you can achieve the breakthrough performance of say Opus 4.1/4.5 in a number of parameters you can swing at home.People used to believe the same about GPT-4, and I'm not convinced this is going to be different this time.
You do need a very big model if you want something that remembers random trivia about everything, but I'm not convinced this is needed to do meaningful work.
by stymaar
5/20/2026 at 1:13:23 PM
> 300B models at least fit in a single maxed out Mac Studio or a small stack of DGX Sparks or AMD Strix Halo boxes.I run 2.54 BPW 397B Qwen 3.5 GGUF on a 128G mac studio at 20 tokens/second generation and 200 tokens/second processing. I'm not suggesting it matches the performance of the full BF16 model, but I did run some benchmarks locally and the results were pretty good:
- MMLU: 87.96%
- GPQA diamond: 86.36%
- IfEval: 91.13%
- GSM8k: 92.57%
So I think we have been at the "frontier capabilities at home" for a few months now.
by tarruda
5/21/2026 at 4:09:44 AM
TurboQuant. They can fit more in less nowby LarsDu88
5/21/2026 at 7:15:21 AM
TurboQuant is a runtime optimization for a model's KV cache and doesn't allow for reduction in model size.by DCKing
5/21/2026 at 5:49:38 PM
TurboQuant reduces the runtime memory needed for the model's KV cache.This reduces both the memory bandwidth needed for inference (at the cost of slightly increasing the amount of compute needed), and the amount of VRAM used overall, meaning more VRAM can be allocated for more weights on the same hardware.
You were replying to a comment estimating model params from hardware. I am saying the param count could be higher for the same hardware.
by LarsDu88
5/20/2026 at 2:56:55 PM
Since I started using Qwen-3.6 35B A3B, I believe frontier like capability will be more than enough in these smaller models within a year or two, at least for coding. They don't need to memorize facts into their weights, which likely has very interesting implications that I'm not going speculatively decodeby verdverm
5/20/2026 at 12:35:20 PM
[dead]by easygenes
5/20/2026 at 5:59:35 AM
Nice post! You piqued my curiosity, so after a bit of research it turns out that, with techniques like MTP/MLA/CSA, it's quite probable that these models are much more efficient (and maybe bigger? tho 400B sounds about right) than a simple RAM breakdown would suggest.MTP - https://blog.google/innovation-and-ai/technology/developers-...
MLA - https://machinelearningmastery.com/a-gentle-introduction-to-...
CSA - https://deepseek.ai/blog/deepseek-v4-compressed-attention
by smnscu
5/21/2026 at 6:14:41 PM
These techniques are used by DeepSeek, and work well with the commodity (NVIDIA) GPU's they use. Google designs their entire AI stack from the custom silicon up. So they have different optimization approaches. (Though Gemma does use MTP)by Doxon
5/20/2026 at 3:06:31 AM
If this is accurate it raises the question: why is this model so expensive? DeepSeek v4 Flash is 284B total/13B active, FP4/FP8 mixed, and only costs $0.14/$0.28 - even less from OpenRouter. Of course Gemini 3.5 Flash is most likely a better product, and therefore it can command a higher price from an economics perspective, but does this imply Google is taking roughly a 90% profit margin on inference? If so they're either very compute-limited or confident in the model and wanting to recoup training/fixed costs (or both).by daemonologist
5/20/2026 at 3:13:24 AM
Well, we use flash models extensively (both 2.5 and 3.1) and I cannot overstate this, google cannot fucking serve them without 503s 70% of the time on most daysI think it’s pure economics. Flash models are OP for the price, leads to too much demand, google cannot serve it. This is likely expensive to reduce load and hey, if it still makes money just keep the margin.
by xmonkee
5/20/2026 at 3:25:20 AM
Rumor is that GCP was happily selling compute to competitors. After all, under the hood, Google is closer to a federation than a corporation. The state of GCP doesn't care about the state of Gemini.by WarmWash
5/20/2026 at 3:48:08 AM
> Rumor isIt’s not a rumor - there are many public announcements about $B deals around compute for other Ai companies
by happyopossum
5/20/2026 at 6:53:39 AM
>> Rumor is that GCP was happily selling compute to competitors. After all, under the hood, Google is closer to a federation than a corporation. The state of GCP doesn't care about the state of Gemini.> It’s not a rumor - there are many public announcements about $B deals around compute for other Ai companies
The last time I read a public announcement, the commentary I read was this is because Anthorpic doesn't want to run out of cash or capacity before a funding round / IPO so they gave Google some equity and in return Google gave it some compute resources? You could reframe it as Google is buying into Anthorpic — which is how Claude tends to frame it as but the end result is the same. Equity for spare capacity.
You could even argue that at a hyperscaler like Google's scale — all capacity is spare capacity and no capacity is spare capacity at the same time. GCP seems to have deals with Anthorpic, OpenAI, Meta, Apple, Healthcare companies, Banks, LG(?), Best Buy(?) so in my mind Google (and all AI vendors) are hyping up AI to drive up interest and building up as fast as they can to capture that interest and convert it into cold, hard cash. It honestly feels like this is out of my mental capacity though because these AI vendors had the cold hard cash that they spent on these data centers that we don't even know might become obsolete within a decade(?) but I guess meanwhile they could make beaucoup bucks. There is also the idea that they had to be seen as conspicuously spending on AI or investors might see them as falling behind, triggering a selloff. So yeah I guess it is a fact that GCP is selling compute to other AI companies but it makes sense because basically you can build capacity potentially for Gemini to use in the future while having other companies pay for some of that cost today.
In my mind, for hyperscalers — Google, Amazon dot com, Microsoft — competitors are not really enemies but rather partners. The real fear or threat is market uncertainty and customers souring on AI altogether. As long as customers are interested in this AI stuff, you could compete on merit or cost benefit ratio but if competitors start failing because they ran out of capacity or cash, that could send an unwanted message to the market.
To summarize though, I have to agree that the supposed rumors are better than rumors, they are facts and we could even make an educated guess that this is a part of a strategy, as much as you can strategize when it comes to an "industry" with a high fixed cost and an uncertain demand.
by collabs
5/20/2026 at 6:57:13 AM
Seems like diversification for the sake to not only maximise profit, but also minimise risk( of their models not keeping competitive).by uHuge
5/20/2026 at 5:28:48 AM
This is the reality of the premiums available from being in the lead by ~8 months on model building technicals.by easygenes
5/20/2026 at 9:14:47 AM
meta - i think that's the first time i've seen a table in a hn comment, and i'm surprised/impressed! niceare these pre-generated in a different tool with plain unicode and then just copy-pasted, or is it a built-in feature of hn?
by 4ggr0
5/20/2026 at 6:58:43 AM
A nice estimate! Since „you can compress knowledge, but not factual knowledge” https://x.com/bojie_li/status/2049314403208896521, it is likely we can actualy measure its size.by stared
5/20/2026 at 12:02:44 PM
I tried to run it, but estimate is 24–33T parameters, vide https://gist.github.com/stared/a86d7380937e6d0ab7920014866ac....It seems to be a huge overshot, vide Hy3 model, which this model claims to be 2.4T, while it is 295B.
by stared
5/20/2026 at 3:37:34 PM
The fact that this is running on tpus is a huge point. Counting those against the other available datacenter hardware used by others, it puts google at a huge advantage, and compute > * while scaling is still workingby wing-_-nuts
5/20/2026 at 2:49:30 AM
Tell me more about what your day looks like. What do you think of the LLMOps books from Abi, in case you have read it ? Any other resources you can recommed?by Maven911
5/20/2026 at 2:34:45 AM
Do you have similar math for the flash-lite variant of the models? I'd be curious. Based on my testing / benchmark i think it's around the 100-120B mark.With the Pro variant being around 600B - 800B
My testing is comparing it's performance / output to other models in the same size range, so not as scientific as yours.
by zacksiri
5/20/2026 at 2:57:52 AM
given this, is it safe to assume that inference pricing is barely related to cost to serve at this point and there is considerable margin?by anthonypasq96
5/20/2026 at 8:34:17 AM
I like your chain of thought there !by rawoke083600
5/20/2026 at 3:24:33 PM
i would like to get a job like that. what can i study? I am mostly a ml engineer / researcher.by PunchTornado
5/20/2026 at 4:27:06 AM
[flagged]by nilstenura
{kind=link}
{kind=link}