This looks really interesting!I _would_ be curious to try it, but...
My first question was whether I could use this for sensitive tasks, given that it's not running on our machines. And after poking around for a while, I didn't find a single mention of security anywhere (as far as I could tell!)
The only thing that I did find was zero data retention, which is mentioned as being 'on request' and only on the Enterprise plan.
I totally understand that you guys need to train and advance your model, but with suggested features like scraping behind login walls, it's a little hard to take seriously with neither of those two things anywhere on the site, so anything you could do to lift up those concerns would be amazing.
Again, you seem to have done some really cool stuff, so I'd love for it to be possible to use!
Update: The homepage says this in a feature box, which is... almost worst than saying nothing, because it doesn't mean anything? -> "Enterprise-grade security; End-to-end encryption, enterprise-grade standards, and zero-trust access controls keep your data protected in transit and at rest."
2/6/2026
at
3:38:50 PM
Thanks for bringing this point up!We take security very seriously and one of the main advantages of using Smooth over running things on your personal device is that your agent gets a browser in a sandboxed machine with no credentials or permissions by default. This means that the agent will be able to see only what you allow it to see. We also have some degree of guard-railing which we will continue to mature over time. For example, you can control which URLs the agent is allowed to view and which are off limits.
Until we'll be able to run everything locally on device, there must be a level of trust in the organizations that control the technology stack, passing from the LLM all the way to the infrastructure providers. And this applies to every personal information you disclose at any touch point to any AI company.
I believe that this trust is something that we and every other company in the space will need to fundamentally continue to grow and mature with our community and our users.
by antves
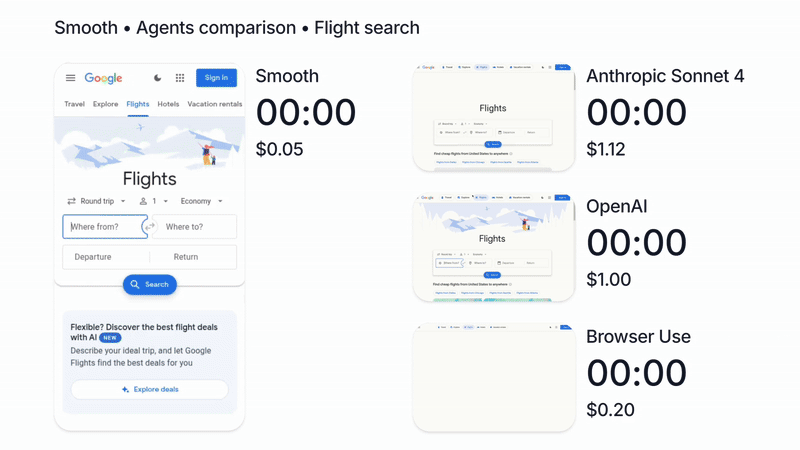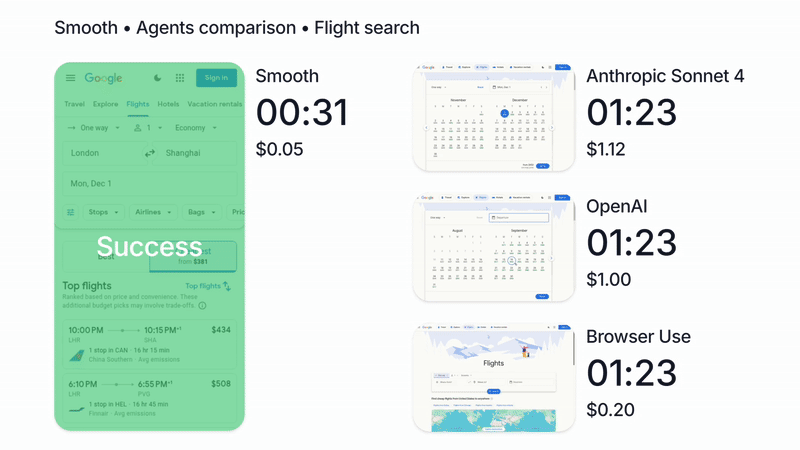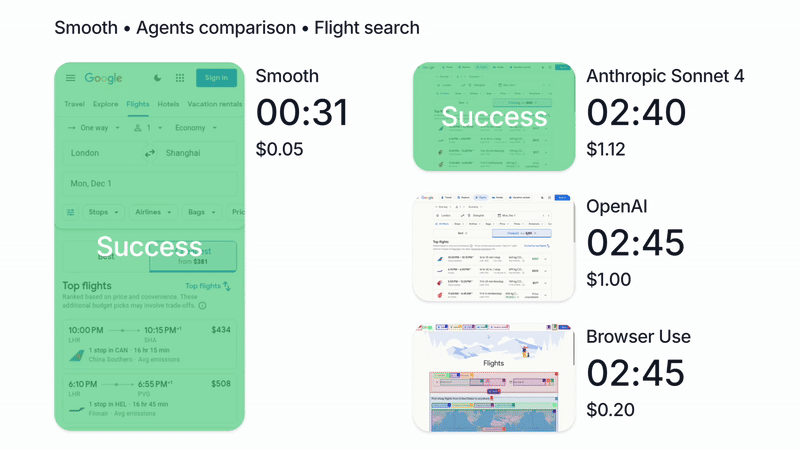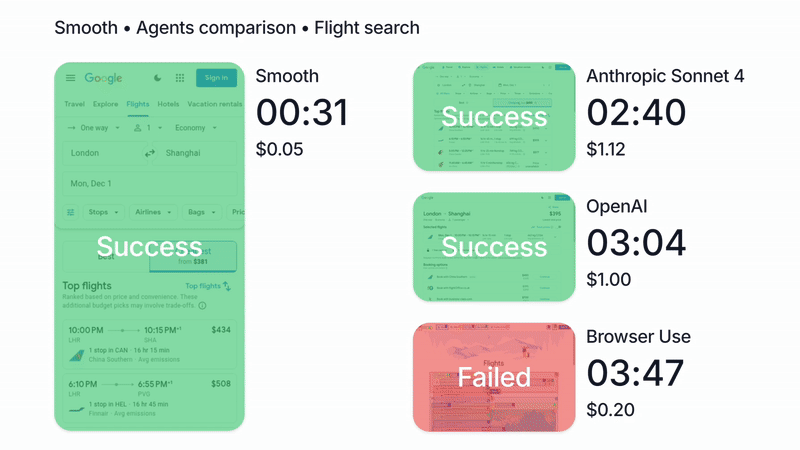{kind=link}